
AI je dnes všude a naši zákazníci hledají způsoby, jak ji využít ve firmách. Sami s AI experimentujeme, a proto jsme vytvořili články s doporučeními a vysvětleními. Články budeme vydávat postupně a začneme rovnou s teorií jazykových modelů.
První článek bude převážně teoretický. Pokud vás zajímají hlavně konkrétní tipy, doporučuji počkat na další články. Nicméně považuji za nezbytné pochopit alespoň základy fungování jazykových modelů. Pokud vás to ale nezajímá, stačí si pamatovat, že veškerý výstup AI je nutné kontrolovat a validovat – ne vždy se jedná o pravdu.
Něco málo o historii
Nebudu vás nudit kompletním přehledem historických milníků umělé inteligence, ale je dobré si uvědomit, že její počátky sahají do 40. let minulého století, kdy byl definován Turingův test.
Po 72 letech vývoje, který se často jevil jako slepá ulička, se AI dostala z oblasti sci-fi a pojmů jako "neuronové sítě" do povědomí většinové společnosti díky praktickým aplikacím. Tento zlom nastal v listopadu 2022 kdy byla spuštěna veřejná veze ChatGPT. Od té doby vznikly další modely, jako například Gemini (Google), Claude, Le Chat, LLaMA a další.
Nicméně, AI pronikala do naší každodenní práce už dávno před listopadem 2022. Automatické odstranění červených očí na fotografiích, chatboti, datové analýzy, převod obrázků na text (OCR) – to vše existovalo ještě před příchodem jazykových modelů, jako je ChatGPT.
Jak fungují jazykové modely
Nebudu zacházet příliš do detailů – není to podstatné a ani já tomu do hloubky nerozumím. Důležité je si uvědomit, že AI vám ve skutečnosti nerozumí. Odpovědi jsou spíše výsledkem statistické analýzy než následek zamyšlení.
AI je neuronová síť. Neuron si můžeme zjednodušit jako prvek, který vezme data, vyhodnotí je a s určitou pravděpodobností určí, co by mělo být výstupem. Výsledek se pak předá dalšímu neuronu, a tak to pokračuje, dokud data neprojdou celou sítí. Výstupem může být například text. Počet a kvalita neuronů tak přímo ovlivňuje úspěšnost modelu.
Neurony rozhodují na základě vah. Čím více dat AI poskytnete, tím lépe se model natrénuje. Důležitým kritériem, které byste měli sledovat u jazykových modelů, je tedy na jakých a kolika datech byl model natrénován.
Skvělým příkladem, jak si to ověřit, je stránka Neural Numbers. Na této stránce můžete zkusit vyhodnocení převodu obrázků na text (OCR), kde stejný model pracuje s různě velkými datovými sadami.
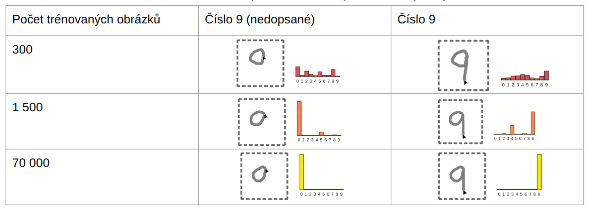
Ve všech příkladech jsem se snažil napsat číslo 9. Pokud je model natrénovaný na 300 obrázcích, může na nedokončeném čísle rozpoznat 0 nebo 9, ale také uvažuje o 2 nebo 5. Pokud však použijeme model trénovaný na 70 000 obrázcích, je si téměř 100% jistý, že jde o nulu, případně po dokončení o číslo 9.
Jak tedy AI pochopí větu nebo ji složí?
Tady vstupuje do hry další matematika, tentokrát s českou stopou. V roce 2010 vydal Čech Tomáš Mikolov nástroj Word2vec, který dokáže matematicky popsat vztahy mezi slovy, větami a odstavci.
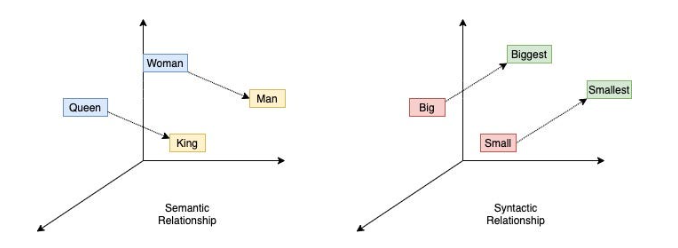
Tyto vztahy lze jednoduše popsat: například rozdíl mezi "velký" a "větší" je stejný jako mezi "malý" a "menší". Když znáte vztahy mezi slovy, slovy ve větě, větami nebo dokonce odstavci, můžete vytvořit program, který složí smysluplnou větu nebo odpoví na otázku.
Porozumění textu
Jazykové modely nepracují s textem jako lidé. Převádějí ho na tzv. tokeny, mezi nimiž vypočítávají vztahy. Na základě těchto vztahů se snaží textu porozumět nebo vytvořit nový. To si můžete vyzkoušet pomocí užitečného nástroje OpenAI Tokenizer.
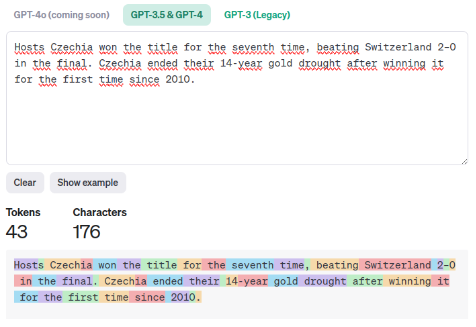
Jak je vidět, token není vždy celé slovo – může to být jen jeho část, nebo třeba tečka. Tento příklad platí pro angličtinu, na kterou jsou jazykové modely dobře trénované díky velkému množství dostupných dat. Naopak v češtině je situace jiná.
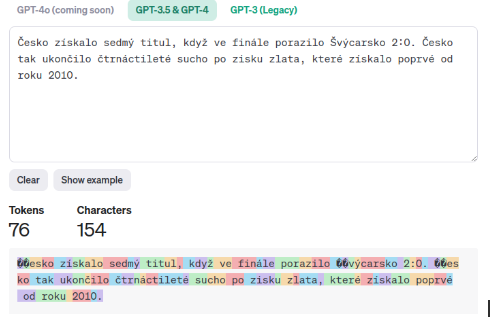
Stejný text v češtině obsahuje téměř dvojnásobek tokenů, i když má méně znaků. Zajímavé je, že například písmeno "Č" se skládá ze dvou tokenů. Pokud se vám zdá, že jazykové modely někdy špatně skloňují, může to být tím, že model statisticky vybral jiný token (písmeno pro dokončení slova). AI nepozná, že výsledek v češtině nedává smysl. Proto je dobré sledovat počet tokenů jako další důležité kritérium.
Vytvoření věty
K pochopení tohoto problému nám OpenAI poskytla užitečný nástroj – OpenAI Playground, který je v podstatě základem ChatGPT. V něm si můžeme vyzkoušet AI bez fine-tuningu a filtrů, a hrát si s nastavením náhody při generování vět.
Jak jsme si již řekli, AI zná vztahy mezi jednotlivými slovy i slovy ve větách. Pokud do Playgroundu zadám část věty „Digitalizace znamená“, AI ji doplní:
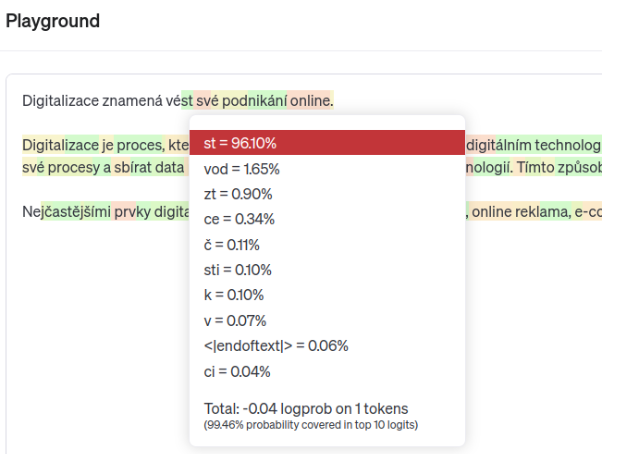
Jednotlivá podbarvení textu ukazují pravděpodobnost použitých tokenů. Můžete najet myší na každý token a zjistit, které slovo AI zvolila a jaké byly další možnosti. AI pracuje s určitou mírou náhody, aby odpověď nebyla jen statisticky přesná, ale také věrohodná. Pokud zvýším míru náhody u stejného zadání, dostanu jiný výsledek:
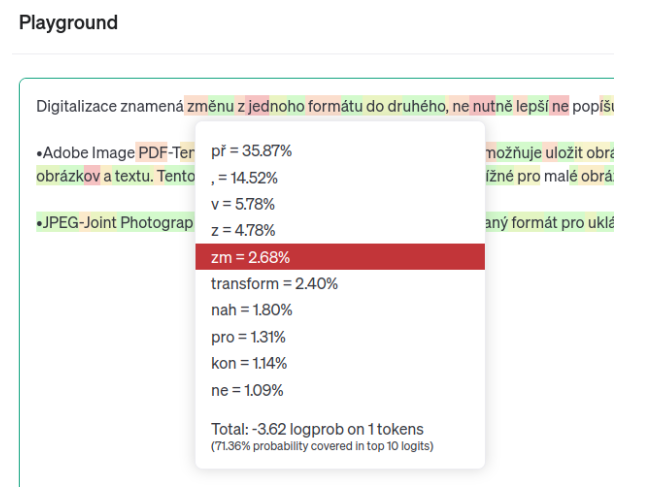
Při zvýšení náhody se změní text i jeho podbarvení. Čím více červené a oranžové, tím je text náhodnější. Například hned první token „zm“ ukazuje, že AI upřednostnila 4. možnost v pořadí místo toho nejpravděpodobnějšího.
Stejným způsobem lze testovat i kontext. Pokud AI zadáte výchozí podmínky, začlení je do svých odpovědí.
Takto „jednoduše“ jazykové modely rozumí textu a generují odpovědi, které očekáváte. Prakticky AI hádá další slovo v pořadí, pokud není odpověď hotová. Nerozumí ani zadání, ani odpovědi. Proto je důležité chatbotům dávat kontext, který zpřesňuje odpovědi, a vždy ověřovat, zda jsou poskytnuté informace pravdivé.
Závěrem
Snažil jsem se vše maximálně zjednodušit. Chápu, že některé informace se mohou zdát zbytečné, ale podle mého názoru jsou tyto detaily klíčové pro lepší ovládání AI. Navíc schopnost správně zadávat prompty (dotazy na AI) je dovednost, kterou si musíme osvojit, podobně jako jsme se kdysi učili googlit. Další články už budou méně teoretické a více praktické.